
[BirdCLEF+] Google Perch
모델 분석, example 코드 이해
Model Overview
- Dataset: Xeno-Canto (10k+ bird species)
- Output: Logits + Embedding vectors
- Embedding이 Logits 보다 더 많은 정보를 가지고 있음.
- Logits are uncalibrated : Logit을 바로 확률로 사용하거나, score threshold 기반으로 판정하는데 즉각 이용하기에는 어려움이 있음. 심지어 out-of-domain일 수도 있음. 하지만 Top-1 분류(가장 확률이 높은 label을 고르는 문제)에서는 크게 문제 없음
Evaluation Strategy
- 5s segments, selected with a peak-detector
- Ground-truth labels assigned per segment
- Audio normalization: Peak-normalize to 0.25
- Handled automatically by Perch library
Used Metrics
- MAP: Mean Average Precision (per example)
- cMAP5: Class-wise MAP, averaged (excludes classes with <5 examples to reduce noise)
- Top-1 Accuracy: Highest logit match (not ideal for multi-label)
Model Architecture
- EfficientNet-B1
Implementation
- Exclude Library, Data loading, Configuration
def bvc_result(ogg):
_, fname, ss_id = ogg
sr = 32_000
print(f'{ss_id}')
row_ids = [f'{ss_id}_{n}' for n in range(5, 65, 5)]
if time.time() > TERMINATE_TIME:
return row_ids, -1000 * np.ones((12, 206))
data, _ = librosa.load(fname, sr=sr)
model_infer = birdclassifier.infer_tf(data.reshape((-1, 5 * sr)))
if config.EMBEDDING :
model_outputs = model_infer['embedding']
result = model_outputs
else :
model_outputs = model_infer['label']
model_outputs = tf.pad(model_outputs, tf.constant([[0, 0], [0, 1]]))
result = model_outputs[:, birdclassifier_indices]
return row_ids, result
- ogg file을 입력시, 5초 단위로 쪼개어 birdclassifier.infer_tf를 거쳐 각 segment에 대한 inference 결과를 출력
- birdclassifier.infer_tf : Dictionary 형태로, key= ‘order’, ‘embedding’, ‘family’, ‘frontend’, ‘genus’, ‘label’ 를 각 segment에 대해 value = tf.Tensor로 출력
Multi-Threading (?)
row_ids = []
result = []
with ThreadPoolExecutor(max_workers=4) as executor:
for ogg_row_ids, ogg_result in executor.map(bvc_result, oggs):
row_ids += ogg_row_ids
result.append(ogg_result)
- ThreadPoolExecutor를 이용하여, multi-threading을 수행할 수 있음.
실험
Test code 실행 :
- submission.csv에 BCF+ submission의 포맷으로 logits가 출력
Embedding Vector 출력 :
- Embedding vector가 궁금하여 이를 출력해본 결과 각 segment에 대해서 1280-vector를 assign함. 각 벡터는 새의 종류에 따라 고유한 방향을 가짐.
- 1280차원을 시각화 하기 어렵기 때문에 PCA로 3차원으로 축소하여, 8개의 soundscape Set에 대해 plotting을 진행
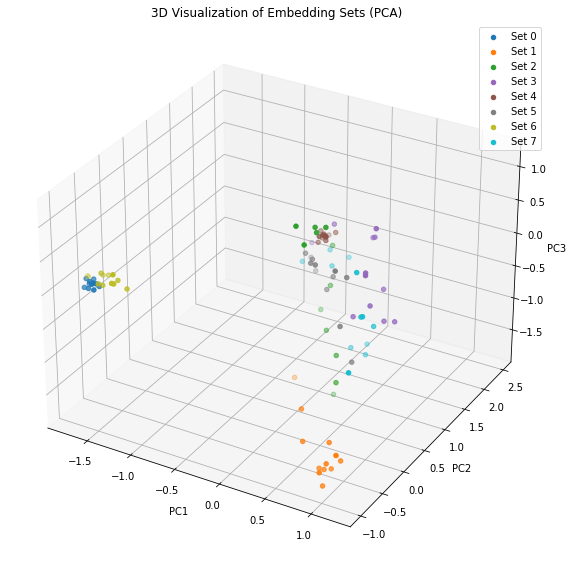
- train_soundscapes 폴더 내의 상위 8개 soundscape에 대하여 다음과 같은 결과를 얻음.
- Logits에 비해 Embedding이 훨씬 풍부한 데이터를 가지고 있다는 점에서, Embedding vector를
Multiclass classification문제에 이용하는 식으로 사전 labeling을 하는 것도 가능해 보임.
댓글을 불러오는 중입니다.